/designer-dresses/
/delivery-information.html
/depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
以上这种问题我们只需要多加一个斜杠就行了 , 如下方所示:
User-agent: *
Disallow: /de/
使用注释给开发者提供说明
注释功能可以向开发者说明robots.txt文件指令的作用 , 如下方所示:
# This instructs Bing not to crawl our site.
User-agent: Bingbot
Disallow: /
搜索蜘蛛会忽略所有以“#”井号开头的robots.txt文件指令 。
针对不同的子域名使用不同的robots.txt文件
robots.txt文件只限于当前根目录域名所使用 , 如果你需要设置其它的域名的robots.txt文件规则 , 那么就需要设置多个robots.txt文件规则 。
例如 , 当前主站域名为www.zhuzhouren.cn , 而你的博客二级域名为blog.zhuzhouren.cn , 那么这种情况就需要设置多个robots.txt文件 , 一个放在主站根目录下 , 一个放在博客网站根目录下 。
Robots.txt文件示例
下面的robots.txt文件示例 , 主要是给站长们一些参考 , 如果这些robots.txt文件指令正好与你要求一样 , 那么你可以将以下robots指令复制粘贴到txt文件中 , 将其另存为robots.txt文件上传至网站根目录中 。
以上robots指令代表的意思是允许所有搜索蜘蛛访问网站所有页面:
User-agent: *
不允许任何搜索蜘蛛抓取网站任何页面
User-agent: *
Disallow: /
禁止所有搜索蜘蛛抓取/folder/这个目录 。
User-agent: *
Disallow: /folder/
禁止所有搜索蜘蛛抓取/folder/这个目录 , 但保留/folder/目录下page.html这个页面可以抓取 。
User-agent: *
Disallow: /folder/
Allow: /folder/page.html
禁止所有搜索蜘蛛抓取this-is-a-file.pdf这个文件
User-agent: *
Disallow: /this-is-a-file.pdf
禁止所有搜索蜘蛛抓取网站pdf文件
User-agent: *
Disallow: /*.pdf$
禁止谷歌蜘蛛抓取带参数的url页面 。
User-agent: Googlebot
Disallow: /*?
如何检测robots.txt文件中的问题?
robots.txt文件是非常容易出错的 , 所以对robots.txt文件的校验也是非常有必要的 , 下面大兵来给大家讲讲robots.txt文件常见错误 , 包括robots文件指令的含义及解决办法:
检验网站某个目录页面是否有错误 , 你可以将robots.txt文件中屏蔽的目录或文件放入Search Console(谷歌资源管理器)的URL Inspection tool(网址检测) , 如果显示被robots.txt文件屏蔽了 , 就如下方所示:
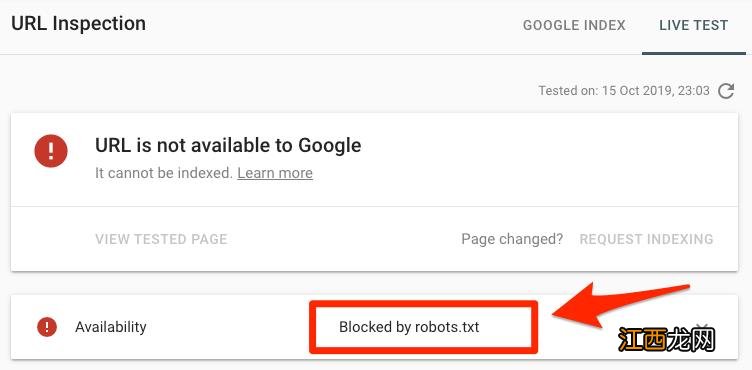
文章插图
国内用户使用百度站长平台也可以进行检测 , 如下图所示:
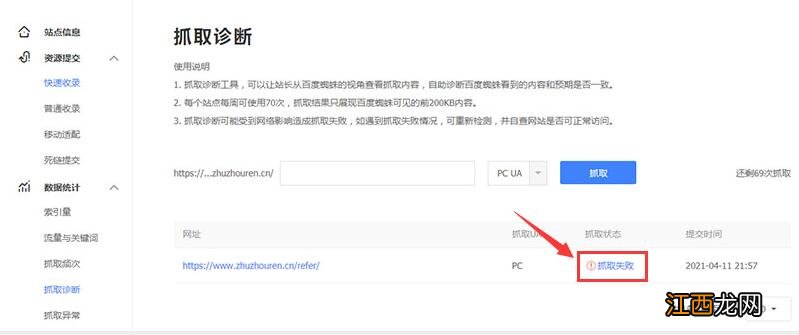
文章插图
显示该目录被robots.txt屏蔽了 , 如下图所示:
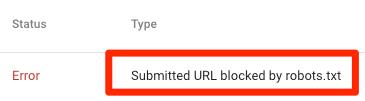
文章插图
上图中意味着此链接在Sitemap文件当中 , 至少有一条url链接被robots.txt屏蔽了 。
如果你的网站地图sitemap文件是正确的 , 页面中并不包含canonicalized、noindexed、redirected等标签 , 而且你所提交的sitemap文件链接没有被robots.txt屏蔽 , 如果检测这个页面链接确实被屏蔽了 , 那么就需要检查被屏蔽的页面 , 再调整robots.txt文件 , 删除相应的robots指令 。
检测网站目录有没有被屏蔽 , 你可以使用谷歌的robots.txt检测工具和百度站长平台robots文件检测工具来检测robots指令 , 在修改robots指令的时候也需要特别小心 , 因为你的修改会影响网站其它目录页面或文件 。
相关经验推荐
















- 上海seo外包:简析互换友情链接有什么作用?
- 网站的内容百度为什么不收录?
- 非常拉风的游戏网名大全霸者才是王道
- 我以为不断笑你就不会分开我。
- 爱上一个人的伤感微信签名:没有人喜欢孤独,只是不愿失望
- 睡觉头东脚西好还是头西脚东好 睡觉头西脚东好不好,床头朝西好还是朝东好
- 头朝西睡觉好不好风水学 睡觉头西是大忌吗,晚上睡觉头朝西好吗
- 床头朝西好还是朝东好 睡觉头朝西,床头的摆放最佳方向
- 地球磁场与睡觉方向 睡觉头朝哪个方向是大忌,风水学睡觉最好的方向
- 睡觉头朝哪个方向最好 睡觉头朝哪个方向好风水学,床头朝西好还是朝东好