
文章图片

文章图片

文章图片
文章图片

一 背景介绍 近日 , TPC Benchmark Express-BigBench(简称TPCx-BB)公布了最新的世界排名 , 阿里云自主研发的神龙大数据加速引擎获得了TPCx-BB SF3000排名第一的成绩 。
TPCx-BB测试分为性能与性价比两个维度 。 其中 , 在性能维度 , 在本次排名中 , 阿里云领先第二名高达41.6% , 达到了2187.42 BBQpm , 性价比领先第二名40% , 降低到346.53 USD/BBQpm 。
(TPCx-BB SF3000性能维度排行)
(TPCx-BB SF3000性价比维度排行)
借这个机会跟大家分享一下这个第一背后的技术历程 。
二 神龙大数据加速引擎MRACC概述 阿里云自研的神龙大数据加速引擎MRACC(Apasara Compute MapReduce Accelerator)是这次取得优异成绩的杀手锏 。
在数据处理需求激增的今天 , 许多企业会使用开源Spark、Hadoop组件或HDP、CDH等常用套件 , 自建开源大数据集群 , 处理数据量从TB到PB级 , 集群规模从几台到几千台 。 MRACC神龙大数据加速引擎 , 针对客户自建场景 , 依托神龙底座 , 提供常用组件加速能力 , 如Spark、Hadoop、Alluxio等 。
结合阿里云神龙架构的特性 , MRACC进行了软硬一体化优化 , 形成独一无二的性能优势 , 最终 , 使复杂SQL查询场景性能相比社区版Spark提升2-3倍 , 使用eRDMA加速Spark性能提升30% 。 在神龙大数据加速引擎的加持下 , 企业使用阿里云ECS云服务器运行大数据集群 , 将获得更高的性能和性价比 。
图1 MRACC神龙大数据加速引擎架构
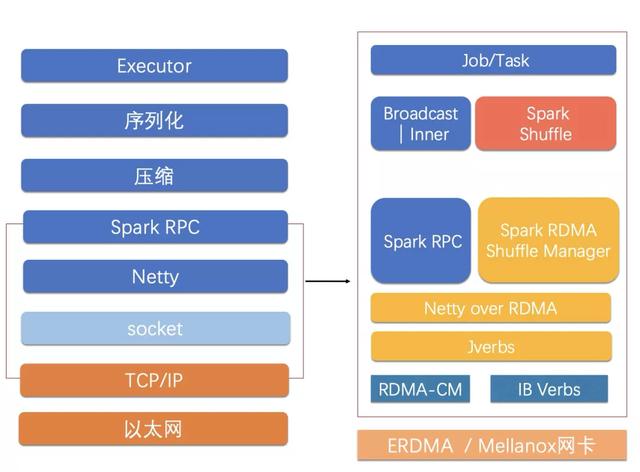
三 MRACC-Spark介绍 Spark自从2010年面世 , 到2020年已经经过十年的发展 , 现在已经发展为大数据批计算的首选引擎 。 针对大数据最常用的Spark引擎 , MRACC进行了重点优化 。 具体来说 , 针对大数据任务重IO特性 , MRACC在网络和存储方面结合云上的架构优势进行软硬件加速 , 包括软件的SQL引擎优化 , 使用缓存、文件裁剪、索引等优化手段 , 并尝试将压缩等运算卸载到异构器件;还使用eRDMA进行网络加速 , 将shuffle阶段的数据交换运行在eRDMA网络 , 使得延时降低、CPU利用率大幅提升 。
图2 MRACC-Spark架构
四 Spark SQL引擎优化 从Spark2以后 , Spark SQL DataFrames and Datasets接口逐渐取代基础RDD API成为Spark的主流编程模型 。 社区对Spark SQL进行了大量投入 , 据统计Spark3.0版本发布将其中接近一半的优化都集中在Spark SQL上 。 使用 SparkSQL 替代 Hive 执行离线任务已成为不少企业的主流选择 。
针对SQL引擎的anlyzer、optimizer、planner、Query execution几个阶段 , 我们都做了一些优化 。 Spark3.0对SQL引擎进行了大刀阔斧的改造和优化 , 其中AQE和DP机制广受关注 。 但目前开源Spark的AE机制目前仅支持分区裁剪 , 对于非分区键和subquery裁剪不支持 , 我们针对这块做了优化 , 支持subquery的动态数据裁剪 , 能大幅减少参与计算的数据量 。
在物理计划执行阶段 , 我们支持了window topn排序 , 使得包含limit的sql语句性能大幅提升 , 并支持了parquet rowgroup裁剪、bloom filter join等高级特性 。 SPAKR SQL的CBO机制能较好的提高SQL执行效率 , 但是在cbo阶段 , join table过多会导致的cbo搜索开销暴增 , 我们支持了遗传算法搜索 , 解决了 join table过多导致的开销暴增的情况 。 此外 , 还支持了去重下推、join外键消除、完整性约束等功能 , 并结合deltalake支持了数据的增删改操作 。
相关经验推荐











- 一加科技|iPhone13Pro、一加9Pro和一加10pro之间,该如何选?
- 小米科技|时讯:MIUI 13稳定版更新,小米12新增内存扩展功能
- 小米科技|Intel/AMD/NV等撑不住!CPU、GPU等今年都要大涨价
- 小米科技|2022拍照最好的几款手机,堪比小单反,经常拍照的可以考虑一下
- 小米科技|12GB+256GB+120W快充,高配陶瓷旗舰机再次跌价,价格更亲民了
- 一加科技|别不舍得花钱,这4款手机一步到位,用个3-5年没问题
- 小米科技|小米手机用一年了,现在电池严重不行,10%以下就自动关机
- 小米科技|三款骁龙8旗舰,续航“测到死”!小米12Pro表现意外
- 小米科技|告别1999!红米K50太强:小米12X很尴尬,但雷军还是出手了
- 小米科技|12+256GB小米手机仅1899元,价格已下跌800,是年前换机的好选择