
文章插图
代码链接:https://github.com/rlleshi/phar
HAR是深度学习领域中一个相对较新的、活跃的研究领域,其目标是从各种输入流(如视频或传感器)中识别人类行为 。
从技术角度看,色情领域很有趣,因为它有一些与众不同的难点,如光线变化、遮挡以及不同摄像机角度和拍摄技术的巨大变化(POV、专业摄像师)使得位置与动作识别变得困难 。两个相同的位置与动作,可能存在多个不同的相机视角拍摄,从而完全混淆了模型的预测 。
作者收集到的数据集非常多样,包括各种录音,如POV、专业拍摄的、业余的、有无专门摄像人员的等等,还包括各种环境、人和摄像机的角度 。
作者也表示,如果只使用专业团队拍摄的影片,这个问题可能不会特别严重 。
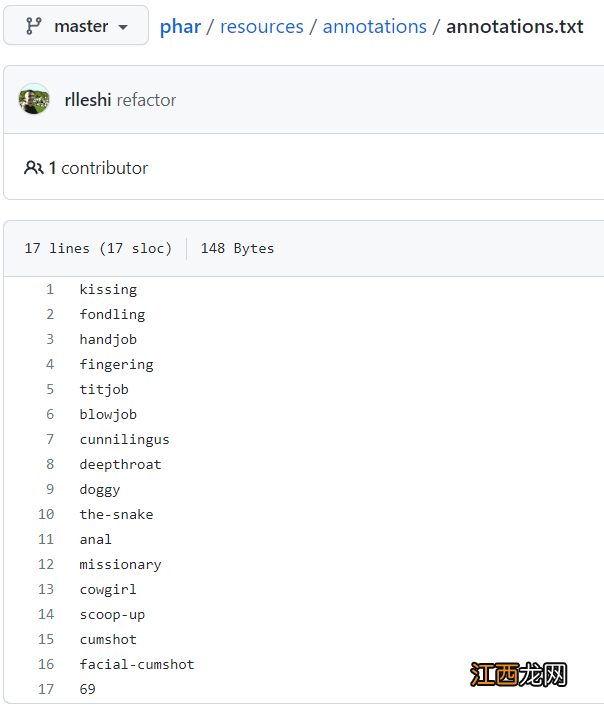
根据收集到的数据集,作者总结了17个动作的识别,如亲吻等,不过动作的定义可能是不全面的,也可能有概念上的重叠 。
其中作者把抚触把玩(fondling)当作一个占位符,没有其他动作类别检测到的时候,就将其视为高清抚触把玩,不过作者在标注数据过程中发现,44小时的影片数据中只得到了48分钟的抚触把玩数据 。
文章插图
项目的实现基于MMAction2,它是一个基于PyTorch的视频理解开源工具箱,可以对人体的骨架动作进行识别等 。

文章插图
取得SOTA结果的模型是通过基于三个输入流的三个模型的后期集成得到的 。
与只使用基于RGB的模型相比,可以取得明显的性能改进 。由于可能不止一个动作观看可能同时发,并且一些动作/位置在概念上是重叠的,所以评价标准以前两名的预测准确性作为性能度量 。
目前多模态模型的准确率为~75% 。但由于数据集相当小,总共只进行了约50次实验,因此有很大的改进空间 。
首先介绍一下在性能和运行时间上都表现最好的多模态(Rgb + 骨架 + 音频)模型 。
作者对视频RGB流使用TimeSformer,爱爱姿势视频,对骨架流使用poseC3D,以及用于音频流的resnet101 。
这些模型的结果通过集成在一起,因为这些模型的重要性不同,所以微调后的权重爱爱是分别是0.5,0.6和1.0

文章插图
另一种方法是一次用两个输入流训练一个模型(即rgb+skeleton和免费rgb+audio),然后将它们的结果集成起来 。
但在实际上,这个操作是不可行的 。
因为如果模型的输入包含音频输入流,它只能对某些动作,比如deepthroat由于咽喉反射导致音调比较高,而对于其他动作,则不可能从其音频中获得任何的有效特征,从音频的角度来看,他们是完全相同的 。
同样,基于在线观看骨架的模型只能用于那些姿势估计准确度高于某个置信度阈值的情况(对于这些实验,所用的阈值是0.4) 。
例如,对于scoop-up或the-snake等高难度稀有动作,由于画面中人体位置比较接近,在大多数相机角度下很难得到准确的姿势估计(姿势变得模糊,混合在了一起),会对HAR模型的准确性产生了负面的影响 。
对于诸如 doggy,cowgirl或missionary等普通动作来说,姿势估计的效果都不错高清,可以用于训练一个HAR模型 。
如果我们有一个更大的数据集爱爱,那么我们可能会有足够视频多的难分类姿势的实例,再用基于骨架的模型训练所有的17个动作 。
相关经验推荐

















- 鸡蛋虾面做法窍门视频 鸡蛋虾面做法窍门
- 芥末拌甘蓝的做法窍门 芥末拌甘蓝的做法窍门视频
- 口味龙虾图片 口味龙虾
- 母乳喂养教学视频腾讯 母乳喂养教学视频
- 脆皖鱼养殖技术,一年成本多少 脆皖鱼养殖技术视频
- 亲子水育早教视频 亲子水育早教
- 兰花可以无土栽培吗 兰花可以无土栽培吗视频
- 小巴掌童话手抄报大全 小巴掌童话手抄报
- 微信自己封面视频怎么弄 微信封面怎么弄成视频
- 怎么给视频加片头 怎么给视频加片头字幕