根据目前的SOTA文献,基于骨架的模型优于基于RGB的模型 。当然,理想情况下,姿势估计模型也应该在sex domain中进行微调,以获得更好的整体姿势估计 。
对于RGB输入流,基于注意力的TimeSformer架构实现了3D RGB模型的最佳结果,推理速度也非常快(~0.53s/7s clips) 。

文章插图
RGB模式总共有~1.76万个训练片段和~4900个评价樱花片段,并应用了各种数据增强技术,如重新缩放、裁剪、翻转、颜色反转、高斯模糊、弹性变换、仿生变换等 。
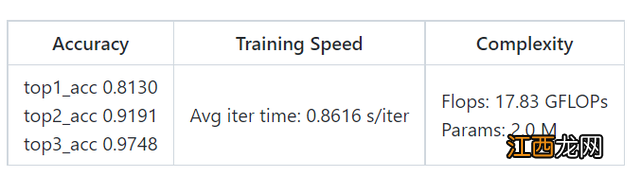
基于骨架模型的最佳结果是由基于CNN的PoseC3D架构实现的,模型的推理速度也很快(~3.3s/7s clips) 。
文章插图
姿势数据集比原始的RGB数据集要小得多,只有33%的帧的置信度高于0.4,所以最终测试集只有815个片段,且目标类别仅为6个 。

文章插图
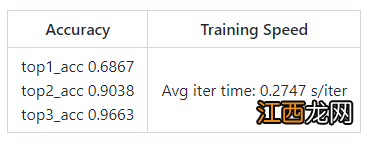
基于语音的模型使用花草了一个简单的ResNet 101,jiyu Audiovisual SlowFast,推理速度非常快(0.05s/7s clips) 。
文章插图
对语音的预处理为从数据集中剪掉不够响亮的音频 。通过修剪最安静的20%的音频,取得了最佳效果 。总共有大约5.9万个训练片段和1.5万个验证片段 。
参考资料:
https://www.reddit.com/r/MachineLearning/comments/va0p9u/p_r_deep_learning_classifier_for_sex_positions/
相关经验推荐

















- 鸡蛋虾面做法窍门视频 鸡蛋虾面做法窍门
- 芥末拌甘蓝的做法窍门 芥末拌甘蓝的做法窍门视频
- 口味龙虾图片 口味龙虾
- 母乳喂养教学视频腾讯 母乳喂养教学视频
- 脆皖鱼养殖技术,一年成本多少 脆皖鱼养殖技术视频
- 亲子水育早教视频 亲子水育早教
- 兰花可以无土栽培吗 兰花可以无土栽培吗视频
- 小巴掌童话手抄报大全 小巴掌童话手抄报
- 微信自己封面视频怎么弄 微信封面怎么弄成视频
- 怎么给视频加片头 怎么给视频加片头字幕