文章图片

文章图片
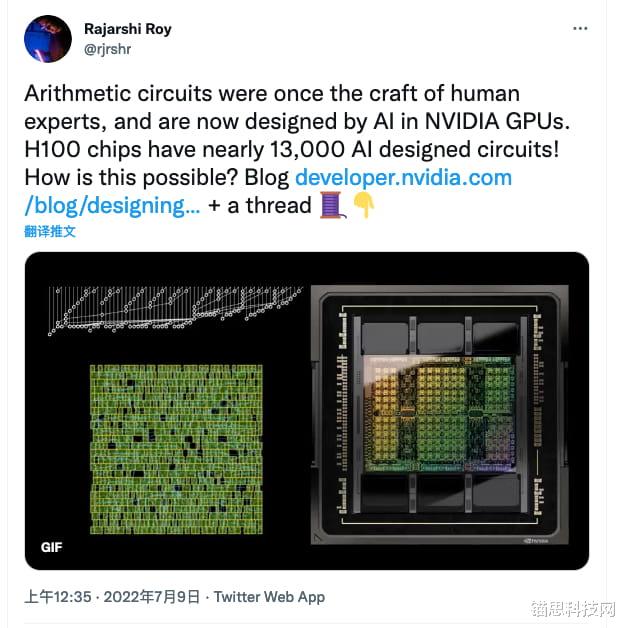
【锚思科技讯】NVIDIA在过去几年中已经成为了人工智能巨头 , 他们的GPU不仅成为HPC的首选 , 也成为了数据中心(包括人工智能和深度学习生态系统)的首选 。 最近 , NVIDIA宣布 , 它正在利用人工智能来设计和开发远远优于人类创建的GPU , 看起来NVIDIA的旗舰Hopper GPU就是对这一声明的证明 , 该声明的特点是近13000个电路实例完全由AI制作 。
在NVIDIA开发者网页上发布的一篇博客中 , 该公司重申了其优势 , 以及它自己是如何利用其人工智能能力来设计迄今为止最大的GPU Hopper H100的 。 NVIDIA GPU大多使用最先进的EDA(电子设计自动化)工具进行设计 , 但借助人工智能 , 利用PrefixRL方法 , 即使用深度强化学习优化并行前缀电路 , 该公司可以设计更小、更快和更节能的芯片 , 同时提供更好的性能 。
计算机芯片中的算术电路是使用逻辑门(如NAND、NOR和XOR)和导线组成的网络构建的 。 理想电路应具有以下特性:
小:一个较低的区域 , 以便在一个芯片上可以容纳更多的电路 。
快速:降低延迟以提高芯片性能 。
功耗更低:芯片功耗更低 。
NVIDIA使用这种方法设计了近13000个人工智能辅助电路 , 与速度和功能相当的EDA工具相比 , 面积减少了25% 。 但PrefixRL是一项计算量非常大的任务 , 对于每个GPU的物理模拟 , 需要256个CPU和32000多个GPU小时 。 为了消除这一瓶颈 , NVIDIA开发了Raptor , 这是一个内部分布式强化学习平台 , 利用NVIDIA硬件的特殊优势进行这种工业强化学习 。
Raptor具有一些增强可扩展性和训练速度的功能 , 例如作业调度、自定义网络和GPU感知的数据结构 。 在PrefixRL的上下文中 , Raptor使工作可以跨CPU、GPU和Spot实例的混合分布 。
此强化学习应用程序中的网络具有多样性 , 并从以下方面受益 。
Raptor能够在NCCL之间切换以进行点到点传输 , 从而将模型参数直接从学习者GPU传输到推理GPU 。
Redis用于异步和较小的消息 , 如奖励或统计信息 。
JIT编译的RPC , 用于处理高容量和低延迟请求 , 如上传体验数据 。
【华硕|NVIDIA Hopper GPU具有13000个人工智能设计电路】NVIDIA得出结论 , 将人工智能应用于现实电路设计 , 可以在未来实现更好的GPU设计 。
相关经验推荐













- AMD|为击败NVIDIA,AMD花3300亿攻关弱项
- 华硕|购机预算有限?5K价位暑期促销笔记本热门机型综合推荐
- 佳能|华硕PB62迷你电脑拆解评测:体积小巧性能强大
- 英伟达|NVIDIA的DLSS游戏支持超过200款 AMD刚追到半山腰
- 华硕zenfone|今年小屏旗舰独苗?华硕Zenfone 9曝光设计
- |华硕 ROG 游戏手机 6,某些硬件电脑看了都得自愧不如
- 华硕|轻薄性能全都要,全方位解读华硕无畏Pro15 2022:真的全能吗?
- mac|又一款性价比轻薄本?华硕a豆新品正式上架,成暑期换电脑首选
- ssd|华硕灵耀Pro16 2022真香开售 酷睿标压+3050Ti助创作潜力尽情释放
- photoshop|AMD+NVIDIA双芯创作本!ROG幻15 2022是否值得选?