
文章插图

文章插图

文章插图
新智元报道
编辑:Joey Aeneas
【新智元导读】文本除了生成图像、视频,还有3D模型!OpenAI最新发布的POINT-E , 输入Prompt一分钟内便可生成3D模型 。
席卷AI世界的下一个突破在哪里?
很多人预测,是3D模型生成器 。
继年初推出的DALL-E 2用天才画笔惊艳所有人之后,周二OpenAI发布了最新的图像生成模型「POINT-E」 , 它可通过文本直接生成3D模型 。

文章插图
论文链接:https://arxiv.org/pdf/2212.08751.pdf
相比竞争对手们(如谷歌的DreamFusion)需要几个GPU工作数个小时,POINT-E只需单个GPU便可在几分钟内生成3D图像 。
经小编实战测试,Prompt输入后POINT-E基本可以秒出3D图像,此外输出图像还支持自定义编辑、保存等功能 。
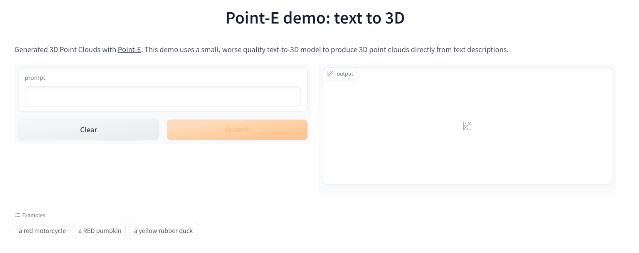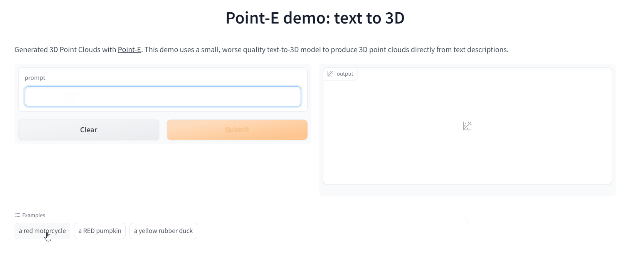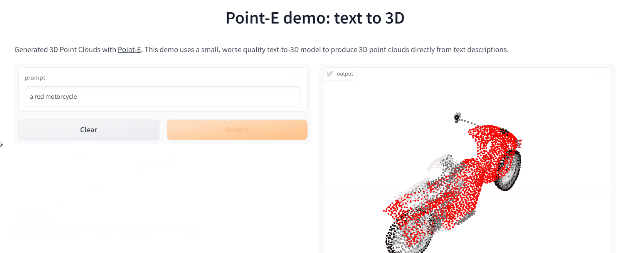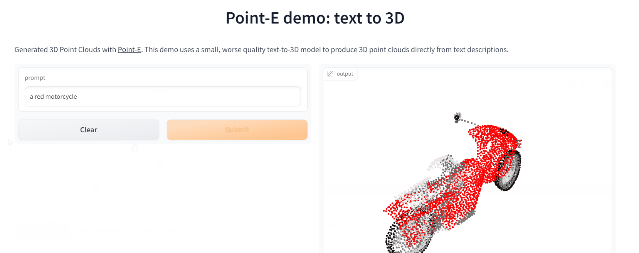
文章插图
地址:https://huggingface.co/spaces/openai/point-e
网友也开始尝试不同的prompt输入 。

文章插图
但输出的结果并不都令人满意 。
文章插图
还有网友表示,POINT-E或许可以实现Meta的元宇宙愿景?
文章插图
需要注意的是,POINT-E是通过点云(point cloud),也就是空间中点的数据集来生成3D图像 。

文章插图
简单来说,就是通过三维模型进行数据采集获取空间中代表3D形状的点云数据 。

文章插图
从计算的角度来看,点云更容易合成,但它们无法捕获对象的细腻形状或纹理 , 这是目前Point-E的一个短板 。
为解决这个限制,Point-E团队训练了一个额外的人工智能系统来将Point-E 的点云转换为网格 。

文章插图
将Point-E点云转换为网格
在独立的网格生成模型之外 , Point-E 由两个模型组成:
一个文本图像转化模型(text-to-image model)和图像转化3D模型(image-to-3D model) 。
文本图像转化模型类似于OpenAI的DALL-E 2和Stable Diffusion,在标记图像上进行训练以理解单词和视觉概念间的关联 。
然后,将一组与3D对象配对图像输入3D转化模型,以便模型学会在两者之间有效转换 。
当输入一个prompt时,文本图像转化模型会生成一个合成渲染对象 , 该对象被馈送到图像转化3D模型,然后生成点云 。
OpenAI研究人员表示 , Point-E经历了数百万3D对象和相关元数据的数据集的训练 。
但它并不完美,Point-E 的图像到 3D 模型有时无法理解文本到图像模型中的图像,导致形状与文本提示不匹配 。尽管如此,它仍然比以前的最先进技术快几个数量级 。
他们在论文中写道:
虽然我们的方法在评估中的表现比最先进的技术差 , 但它只用了一小部分时间就可以生成样本 。这可以使它对某些应用程序更实用,并且发现更高质量的3D对象 。相关经验推荐
- 一颗苹果树产量多少斤,苹果树几月份修剪比较好
- 第一颗原子弹叫什么 关于第一颗原子弹的介绍
- 阿门阿前一颗葡萄树这首歌名是什么 这首歌的完整歌词
- 英特尔显卡部门拆分,是英特尔GPU成功的必经之路?
- 离谱!家长带小孩去矫牙,竟发现孩子鼻腔内有一颗围棋
- 第一次吃金毓婷很害怕怎么办-吃了一颗金毓婷为啥一点反应都没有正常吗
- 显卡出货量破二十年新低!红绿蓝三家混战,国产GPU引起海外关注
- 烤瓷牙多少钱一颗
- 一颗如意皇后怎么繁殖
- 一颗红枣有多少热量 红枣含有哪些营养成分













