其实 , 对于语音识别这类和语音有关的几个常见的AI功能——没错 , 是AI应用 , 模型都给你训练好了的——往往一行代码(核心实现)就能实现 , 不过为了谨慎起见 , 还是不要那么说吧 , 毕竟一行终端命令是一个功能 。 这个很厉害的AI就是百度飞桨的Speech , 其实就是PaddleSpeech啦 。
这是PaddlePaddle里的项目 。 PaddleSpeech基于飞桨PaddlePaddle的语音方向的开源模型库 , 用于语音和音频中的各种关键任务的开发 , 包含大量基于深度学习前沿和有影响力的模型 。 也就是封装了语音识别语音翻译等多个我们常用的功能 。 之前在很多AI应用上一直用国外的开源项目 , 虽然一直听说PaddlePaddle但没在意 , 后来用了某个一试 , 果然啊 , 比较符合胃口(门槛低呗) 。
如果我们想要做一个语音识别的小应用 , 或者就是想要体验一下 , 可以试试PaddleSpeech这个 。 机智客简单试了下 , 感觉效果还是很棒的 。 由于这是基于飞桨的PaddleSpeech , 所以我们在配置环境的时候就要安装飞桨的库 , 保证环境里有PaddlePaddle或者创建新的虚拟环境 , 安装飞桨 。 再用pip安装paddlespeech就行 。 这里官方强烈建议在Linux下 , 而且是3.7以及以上版本的Python , 由于自己用的是Ubuntu , 之前默认的Python就完全符合 , 这一步不存在障碍 。
等待安装成功 , pip检查没有问题 , 就可以测试使用语音识别这些功能了 。 比如我们在本地文件夹里放一个测试的wav文件 , 然后用输入paddlespeech asr --lang zh --input 0.wav这样的命令开始识别 。 当然 , 这里没有加路径 , 说明是在当前目录里开的终端 。 然后执行命令 。 此时会加载数据 , 然后会自动下载模型 , 下载PaddleSpeech需要的whl文件也就是paddlespeech_ctcdecoders-0.1.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl 。 文件并不大 , 不过之后有很多代码输出 , 安静等着就行了 。
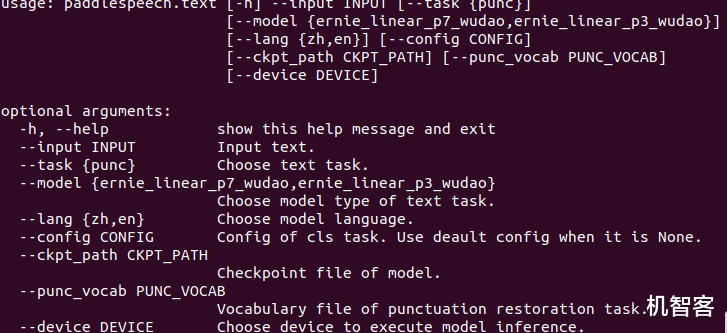
【华为|几行代码的事儿,语音识别翻译合成克隆一条龙AI功能都有】等到结束了 。 正确的识别输出就出来了 。 当然这里是输出到终端里的 , 我们能直接看到 。 而paddlespeech命令还有很多参数和要求 , 我们可以在项目说明里查看文档 , 或者在终端用help查看相关说明 。 这只是一个小例子 , Paddlespeech有很多内置的模型 , 也就是有很多相应的应用 , 方便我们直接调用 。 大家可以试一下 。
相关经验推荐













- 华为鸿蒙系统|蒙系统的那些卡片功能,也就是刚面世时候的噱头,用下来用处不大
- 华为|不可否认,华为做的事情,客观上让我们有了一个好的标杆
- 华为荣耀|9999元起售!国产“折叠屏性能王”诞生,荣耀逐步收复华为失地
- 华为鸿蒙系统|鸿蒙功耗很不错,比以前耐用一些,系统也增加了一些小功能
- 红米手机|中国的操作系统路在何方,华为鸿蒙系统普及路难, 新plug操作系统
- 华为|华为上架新机,搭载麒麟芯片,5000mAh仅售1399元
- |创小报151: 华为进军私募;蚂蚁减持众安保险;佳能进军造车;马斯克
- 华为|2021年,最大苹果的三大槽点
- iPhone|不想抄袭华为?iPhone14感叹号挖孔不支持高刷,供应链产能不足!
- 华为手机|华为手机拍照不好看?新手必看指南