
文章插图
Robot.txt文件
一、robots.txt文件基础知识讲解
Disallow:这个函数后面加某个目录url地址则表示的意思是禁止搜索引擎抓取收录的页面,如果禁止全站抓取索引,则Disallow:后面不加任何东西,
Allow:这个函数后面加的数值表示的意思是允许搜索引擎访问索引的URL地址,这个数值可以是一条完整的URL路径地址,也可以是某些url目录地址的前缀,例如“Allow:/zhishi”,表示的是允许搜索引擎访问/zhish.html、/seozhishi.html,也可以是/zhish/123.html,网站其它的url地址既没有加Allow也没有加Disallow,那么这些url地址就是默认允许被访问的,所以Allow和Disallow一般都是搭配使用的,如果要实现允许搜索引擎访问一部分网页同时又要禁止访问其它所有URL的功能,那么我们可以使用通配符”*”and”$”:Baiduspider,”*”和”$”是用来来模糊匹配url地址的 。
“*” 可以匹配0或多个任意字符;
“$” 则表示匹配行结束符 。
第二:设置Robots.txt文件时应注意哪些事项?
robots文件往往放置于根目录下,包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
“
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样 。 该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:该项的值用于描述搜索引擎robot的名字 。 在”robots.txt”文件中,如果有多条User-agent记录说明有多个robot会受到”robots.txt”的限制,对该文件来说,至少要有一条User-agent记录 。 如果该项的值设为*,则对任何robot均有效,在”robots.txt”文件中,”User-agent:*”这样的记录只能有一条 。 如果在”robots.txt”文件中,加入”User-agent:SomeBot”和若干Disallow、Allow行,那么名为”SomeBot”只受到”User-agent:SomeBot”后面的 Disallow和Allow行的限制 。
Disallow:该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问 。 例如”Disallow:/help”禁止robot访问/help.html、/helpabc.html、/help/index.html,而”Disallow:/help/”则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html 。 ”Disallow:”说明允许robot访问该网站的所有url,在”/robots.txt”文件中,至少要有一条Disallow记录 。 如果”/robots.txt”不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的 。
Allow:该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的 。 例如”Allow:/hibaidu”允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html 。 一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能 。
使用”*”and”$”:Baiduspider支持使用通配符”*”和”$”来模糊匹配url 。
“*” 匹配0或多个任意字符
“$” 匹配行结束符 。
最后需要说明的是:百度会严格遵守robots的相关协议,请注意区分您不想被抓取或收录的目录的大小写,百度会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议无法生效 。
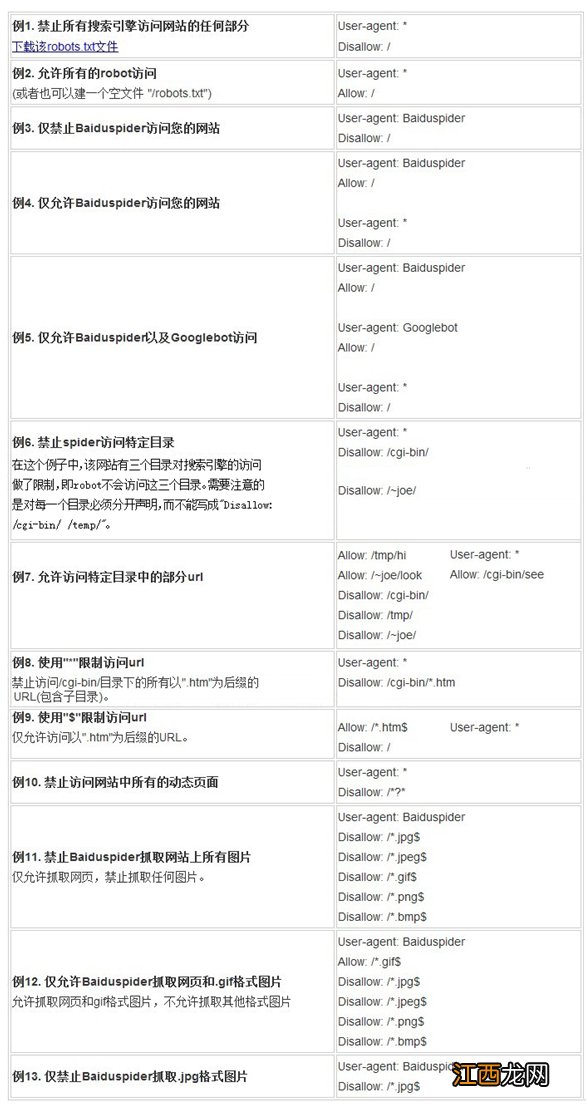
robots.txt文件用法举例:
【Robot.txt文件要如何正确设置】
相关经验推荐
















- 广安seo:杭州网站建设的重要性
- 喝水的作用胜过吃药,及时补水非常重要!一定要看
- 鸭蛋放冰箱前要洗吗
- 淹鹅蛋需要多长时间
- 腌糖蒜需要放水吗
- 为什么要裹脚
- 为什么要围垦
- 为什么游泳前要拉伸
- 白羊座内心接近神 不要看白羊女的眼睛,3月白羊vs4月白羊
- 新的冰丝凉席要清洗吗