
文章插图

文章插图

文章插图
新智元报道
编辑:LRS
【新智元导读】强化学习也要进入预训练时代了!
基础模型(foundation models) 在监督和自监督学习问题上展现出强大的领域适应性(adaption)和可扩展性(scalability),但强化学习领域仍然没有基础模型 。
最近DeepMind的Adaptive Agents团队提出了一种 人-时间尺度(human-timescale)自适应智能体AdA(Adaptive Agent) , 证明经过大规模训练后的RL智能体也能具有通用上下文的学习能力,该算法可以像人一样快速适应开放式的具身3D问题 。

文章插图
论文链接:https://arxiv.org/abs/2301.07608
在一个巨大的动态空间环境中,自适应智能体展现出即时的假设驱动的探索,能够有效地利用获得的知识,而且可以接受第一人称演示作为提示(prompt) 。
研究人员认为其适应性主要来源于 三个因素 :
1. 在一个巨大的、平滑的和多样化的任务分布中进行元强化学习;
2. 一个参数化的、基于注意力的大规模记忆结构的策略;
3. 一个有效的自动curriculum,在代理能力的前沿对任务进行优先排序 。
实验部分展示了与网络规模、记忆长度和训练任务分布的丰富程度有关的特征性扩展规律;研究人员认为该结果为日益普遍和适应性强的RL智能体奠定了基?。悄芴逶诳帕煊蚧肪橙匀槐硐至己?。
RL基础模型
人类 往往能够在 几分钟内适应一个新的环境,这是体现人类智能的一个关键特性,同时也是通往通用人工智能道路上的一个重要节点 。
不管是何种层次的有界理性(bounded retionality),都存在一个任务空间,在这个空间中,智能体无法以zero-shot的方式泛化其策略;但如果智能体能够非常快速地从反馈中学习 , 那么就可能取得性能提升 。
为了在现实世界中以及在与人类的互动中发挥作用,人工智能体应该能够在「几次互动」中进行快速且灵活的适应,并且应该在可用数据量提升时继续适应 。
具体来说,研究人员希望训练出的智能体在测试时,只需要在一个未见过的环境中给定几个episode的数据,就能完成一个需要试错探索的任务,并能随后将其解决方案完善为最佳的行为 。
元强化学习(Meta-RL) 已经被证明对快速的语境适应是有效的 , 然而,不过元RL在奖励稀疏、任务空间巨大且多样化的环境中作用有限 。
这项工作为训练RL基础模型铺平了道路;也就是说 , 一个已经在庞大的任务分布上进行了预训练的智能体 , 在测试时,它能以few-shot的方式适应广泛的下游任务 。
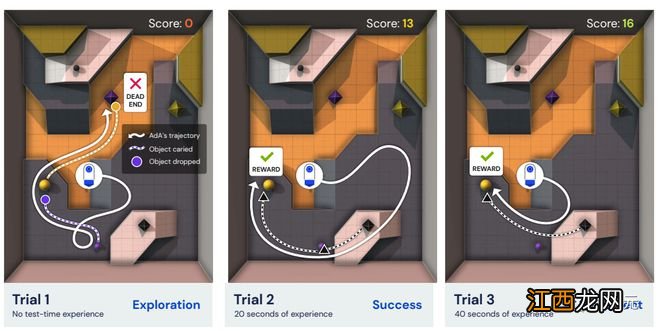
自适应智能体(AdA)能够在具有稀疏奖励的巨大开放式任务空间中进行人类时间尺度适应,不需要任何提示、微调或访问离线数据集 。
相反,AdA表现出假设驱动的探索行为,利用即时获得的信息来完善其策略,能够有效地获取知识 , 在第一人称像素观察的部分可观察的三维环境中,在几分钟内适应奖励稀疏的任务 。
文章插图
自适应智能体Ada
研究人员提出了一种基于记忆的元RL通用和可扩展的方法以生成自适应智能体(AdA)
首先在XLand 2.0中训练和测试AdA,该环境支持按程序生成不同的三维世界和多人游戏,具有丰富的动态性,需要智能体拥有足够的适应性 。
相关经验推荐












- 怎样教孩子学习绘画 如何教孩子学习绘画
- 怎么能让孩子主动学习
- 一轮复习地理学习重点 有哪些重点地理知识点
- 《仙乐传说加强版》游戏强化功能和画面参数公布
- 松乳菇的种植技术在哪里可以学习
- 对话华创资本合伙人熊伟铭:冰封重启,2023年投资市场 “有风景也有迷雾”
- 孩子怎样才能学习好
- 学习书法的好处有哪些?,学书法的好处是什么?
- 怎么学习温室工程
- 古人也有食物造假吗,古代怎么监管食品安全