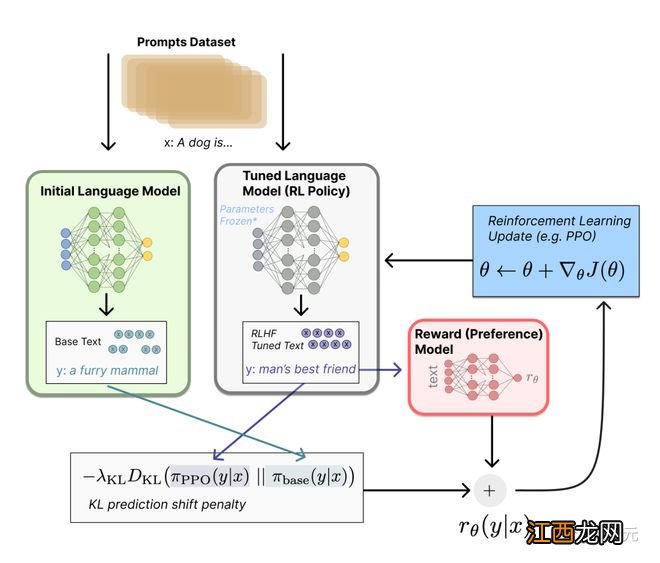
文章插图
RLHF可以通过迭代更新奖励模型和策略,从这一点继续 。
随着RL策略的更新 , 用户可以继续将这些输出与模型的早期版本进行排名 。
这个过程中 , 就引入了策略和奖励模型演变的复杂动态,这个研究非常复杂,非常开放 。
参考资料:
https://www.4gamers.com.tw/news/detail/56185/chatgpt-can-have-a-good-conversation-with-you-among-acg-and-trpg-mostly
https://www.businessinsider.com/history-of-openai-company-chatgpt-elon-musk-founded-2022-12#musk-has-continued-to-take-issue-with-openai-in-recent-years-7
相关经验推荐














- 懂不懂歌词 懂不懂歌词分配
- 6种毁掉孩子的教育方式六种不良教育 6种毁掉孩子的教育方式是什么
- 蓝莓是不是越大越好 蓝莓吃了有哪些好处
- 豇豆不熟会中毒吗 豇豆中毒多久有反应
- 油豆腐怎么保存不易坏 怎么挑选好的豆腐
- 便秘吃什么最快排便 便秘的症状虚实不同
- 郭子仪什么水平 郭子仪为什么功高不自傲
- 紫生菜不能同什么搭配
- 怀孕什么都不想吃怎么办 怀孕什么都不想吃怎么做
- 姜枣茶一次的量是多少 隔夜的姜枣茶可不可以喝