文章图片
为什么要做压测 【创投圈|如何做“健康码”的性能压测】随着无线设备的普及和 5G 的大力建设 , 越来越多的线上系统、小程序成为了人们生活中必不可少的工具 。 对于这些工具 , 都会面对一个问题:系统能承受多少用户同时访问 , 面对突发的流量洪峰 , 能否保证系统无故障稳定运行?
为了回答这个问题 , 就需要在系统上线前做多轮压力测试 , 提前模拟出复杂的 高仿真的线上流量来验证整体系统的高可用性 这也是实施系统高可用方案的关键环节 。 另外通过不同阶段的压测 , 也完成对系统的容量规划、瓶颈探测 , 对系统整体能力进行验收 , 确保在突发的流量洪峰来临前 , 系统确实能够承受即将来临的真实线上压力 。
从某种意义上来说 , 压测是系统稳定性的验证者 。
如何实施一次准确的性能压测
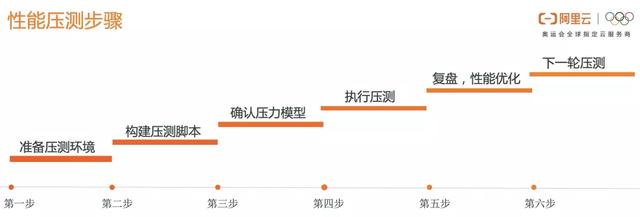
准备压测环境
压测的执行环境是一个老生常谈的话题 , 如果直接在生产环境执行压测 , 会有2个问题:
会影响线上业务 , 对正常访问系统的用户造成影响 会污染线上数据 , 将压测数据写入线上数据库 为了解决这 2 个问题 , 一般业内采用如下几种方案: 以上方案各有优缺点 , 适用场景也不尽相同 , 可以根据自己项目所处的阶段灵活选择方案 。构建压测脚本 业内常用的压测工具包括 JMeter、Gatling、Locust、k6、Tsung、阿里云 PTS 等 。 这些工具无一例外 , 都需要将压测业务的 API , 编排为一个压测脚本 。这一步工作的重点在确认压测的 API , 不要有遗漏 , 且 API 编排的顺序要符合用户的操作逻辑 。 对于健康码业务的压测来说 , 如果脚本中遗漏了登录鉴权 API , 那后面的刷新健康码、查看核酸报告等 API 都会在权限校验这步就报错 , 不会执行正常的业务逻辑 , 也就无法模拟真实的业务场景 。 以上压测工具编排脚本都有 2 个方式: 手动输入脚本 , 这需要脚本的编写人员对业务非常熟悉 , 保证不会遗漏API 。自动录制脚本 , 上述开源压测工具都提供了录制请求的代理功能 , 开启并配置代理后 , 只要在页面上模拟用户的操作和点击行为 , 即可自动录制请求 , 并生成压测脚本 。 同时 PTS 还提供了 Chrome 录制插件[1
, 免代理配置 , 可以一键生成 JMeter 和 PTS 压测脚本 。 提升了脚本编写的效率 , 也能保证不遗漏 API 。为了避免复杂脚本中遗漏 API 的风险 , 推荐使用录制功能生成脚本 。确认压力模型 这一步是在配置压测中模拟的压力峰值、不同 API 的压力分布比例以及压力值递增模型 。 压力值指的是模拟并发用户数 , 或每秒发送的请求数 。施压模式 在设置之前 , 需要确认施压模式 , 业内主要有 2 种施压模式: 虚拟用户(VU)模式 , 可以理解为一个线程模拟一个真实用户 , 压测时线程一直循环执行 , 模拟用户不停地发送请求 。吞吐量模式 , 即每秒请求数(QPS) , 可以直接衡量服务端的吞吐量 。在项目验收阶段 , 很重要的一个指标就是系统的吞吐量 , 即可支持的QPS 。 对于这种压测场景 , 更推荐使用吞吐量模式 , 可以直观的看到施压机每秒发出的请求数 , 并和服务端的吞吐量直接对应起来 。各 API 压力分布比例 确认了施压模式后 , 需要配置不同 API 的压力分布比例 。 比如健康码业务 , 100% 的用户会调用登录 AP 和获取健康码 API , 但后面并不是所有用户都会调用查询核酸报告 API、查看推送信息等 API 。 所以每个 API 的准确压力分布比例 , 也是一次成功压测中不可获取的因素 。压力值递增模型 常见有脉冲模型 , 阶梯递增 , 均匀递增 。脉冲模型会模拟流量在瞬间突然增大 , 常用于秒杀、抢购的业务场景 。递增模型可以模拟在一定时间段内 , 用户量不断增大 , 常用于模拟有预热的业务场景 。除了常规的递增模型 , 最好在压测中可以实现手动调速功能 , 一是可以模拟一些非常规的流量递增情况 , 二是可以反复调整压力值 , 来复现和排查问题 。施压流量地域分布 确定了压力值和递增模型后 , 还需要确定施压流量的地域分布 , 应尽量拟合真实的用户分布 , 才能保证测试结果真实可信 。对于区域性的在线业务 , 施压机分布在当地的同一机房 , 是可以理解的 。 如果是全国性的在线业务 , 施压机也应该按照用户分布 , 在全国各地域部署 。执行压测 , 观察压测指标 压测中核心指标:请求成功率 , 请求响应时间(RT) , 系统吞吐量(QPS) 请求成功率不止要看全局的请求成功率 , 还要关注一些核心API的成功率 , 避免整体成功率达标 , 核心 API 成功率不足的情况 。请求响应时间 , 需要关注 99、95、90、80... 等一些关键分位的指标是否符合预期 , 而平均响应时间没有太大的参考意义 , 因为压测需要保证绝大部分用户的体验 , 在不清楚离散程度的情况下 , 平均值容易造成误判 。系统吞吐量是衡量系统能承受多大访问量的指标 , 是压测不可缺少的标准 。上面三个指标遇到拐点时 , 就可以认为系统已经出现性能瓶颈 , 可以停止压测或调小压力值 , 准备分析、定位性能问题了 。除了这三个业务指标 , 同时还应该同时观测系统的应用监控、中间件监控和硬件监控的一些指标 , 包括但不限于: 服务器: 网络吞吐量 CPU 使用率 内存使用率 磁盘吞吐量 ...... 数据库: 连接数 SQL 吞吐量 慢 SQL 数 索引命中率 锁等待时间 锁等待次数 ..... 中间件: JVM GC 次数 JVM GC 耗时 堆内、堆外内存使用量 Tomcat 线程池活跃线程数 ...... 更多压测时需要关注的指标 , 见压测指标[2
相关经验推荐










- 耳机|如何避免耳机带来的伤害
- 摄影|该如何选择自拍手机?vivo有款新机可以当作标准线
- Windows11|Win11操作系统,卓越性能模式如何开启?win11卓越模式开启方法
- 苹果|B660主板+英特尔12400CPU,性价比搭配效果如何实测?
- 英特尔|iQOO9和小米12Pro相比较,该如何选?
- 红米手机|红米k40、小米10S和小米12X之间,该如何选?
- 显卡|iqooz5和真我q3s相比较,该如何选?
- 安卓|三星s22ultra和华为P50pro相比较,该如何选?
- 苹果|苹果iPhone如何充电才能保护电池?官方:避开这个温度!
- 华为nova9|华为nova9和vivoS12相比较,该如何选?