
文章插图

文章插图
新晋图像生成王者扩散模型,刚刚诞生没多久 。
有关它的理论和实践都还在“野蛮生长” 。
来自英伟达StyleGAN的原班作者们站了出来,尝试给出了一些设计扩散模型的窍门和准则 , 结果模型的质量和效率都有所改进,比如将现有ImageNet-64模型的FID分数从2.07提高到接近SOTA的1.55分 。

文章插图
他们这一工作成果迅速得到了业界大佬的认同 。
DeepMind研究员就称赞道:这篇论文简直就是训练扩散模型的人必看,妥妥的一座金矿 。
我们从以下几个方面来看StyleGAN作者们对扩散模型所做的三大贡献:
用通用框架表示扩散模型
在这部分 , 作者的贡献主要为从实践的角度观察模型背后的理论,重点关注出现在训练和采样阶段的“有形”对象和算法,更好地了解了组件是如何连接在一起的 , 以及它们在整个系统的设计中可以使用的自由度(degrees of freedom) 。
精华就是下面这张表:

文章插图
该表给出了在他们的框架中复现三种模型的确定变体的公式 。
(这三种方法(VP、VE、iDDPM+ DDIM)不仅被广泛使用且实现了SOTA性能,还来自不同的理论基础 。)
这些公式让组件之间原则上没有隐含的依赖关系,在合理范围内选择任意单个公示都可以得出一个功能模型 。
随机采样和确定性采样的改进
作者的第二组贡献涉及扩散模型合成图像的采样过程 。
他们确定了最佳的时间离散化(time discretization),对采样过程应用了更高阶的Runge–Kutta方法,并在三个预训练模型上评估不同的方法 , 分析了随机性在采样过程中的有用性 。
结果在合成过程中所需的采样步骤数量显着减少,改进的采样器可以用作几个广泛使用的扩散模型的直接替代品 。
先看确定性采样 。用到的三个测试模型还是上面的那三个,来自不同的理论框架和模型族 。
作者首先使用原始的采样器(sampler)实现测量这些模型的基线结果,然后使用表1中的公式将这些采样方法引入他们的统一框架,再进行改进 。
接着根据在50000张生成图像和所有可用真实图像之间计算的FID分数来评估质量 。
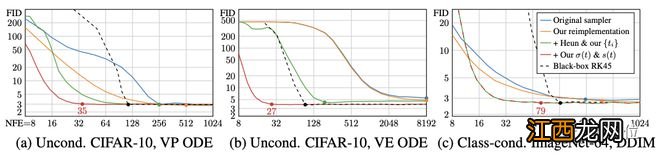
文章插图
可以看到 , 原始的的确定性采样器以蓝色显示,在他们的统一框架(橙色)中重新实现这些方法会产生类似或更好的结果 。
作者解释,这些差异是由于原始实现中的某些疏忽,加上作者对离散噪声级的处理更仔细造成的 。
确定性采样好处虽然多,但与每一步都向图像中注入新噪声的随机采样相比,它输出的图像质量确实更差 。
不过作者很好奇,假设ODE(常微分方程)和SDE(随机微分方程)在理论上恢复相同的分布,随机性的作用到底是什么?
在此他们提出了一种新的随机采样器,它将现有的高阶ODE积分器与添加和去除噪声的显式“Langevin-like ‘churn’”相结合 。
最终模型性能提升显著,而且仅通过对采样器的改进,就能够让ImageNet-64模型原来的FID分数从2.07提高到1.55,接近SOTA水平 。

文章插图
预处理和训练
相关经验推荐




![[穿越火线]BS.F演绎视觉盛宴,以绝对枪法击败完美体系](https://imgcdn.toutiaoyule.com/20210907/20210907065304750628a_t.jpeg)








- 影之诗国际服谷歌无法联动 影之诗怎么联动谷歌
- 航空业的复古时代?谷歌创始人的秘密项目:电动飞艇
- 谷歌推新绩效考核体系 或有超过1万名员工不达标
- 带谷歌云业绩翻几番,CEO库里安的秘诀是什么?
- 谷歌万国觉醒国际服怎么登,万国觉醒国际服怎么登录
- 影之诗怎么解绑谷歌 影之诗怎么解绑steam
- 影之诗怎么解绑谷歌,影之诗谷歌账号联动失败
- 华为怎么安装谷歌商店 怎么安装谷歌商店
- 苹果11怎么关谷歌浏览器 苹果11怎么关谷歌
- 影之诗怎么联动谷歌,影之诗谷歌解绑